Resume Builder: The ATS Intelligence Engine
Why AI-powered resume tailoring is not a productivity tool — it is a structural equalizer for a hiring market built on algorithmic gatekeeping.
“The applicant tracking system does not evaluate talent. It pattern-matches text against a keyword template. The strategic response is not to game the system — it is to understand it with precision and communicate through it without losing authenticity.”
Paper DNA
Domain
Career Intelligence
Maturity
Live
Market Size
Recruitment software $3.4B · Job seekers: 10M+ actively searching (US)
75% of resumes submitted to enterprise applicant tracking systems are rejected before a human reads them — not because the candidate was unqualified, but because the resume failed to match ATS parsing rules, keyword templates, or formatting constraints the candidate had no visibility into.
The Resume Builder addresses this structural information asymmetry with an AI engine that reads the job description as the ATS will, identifies the gap between it and the candidate's current resume, and produces a tailored, ATS-optimized version in seconds — not hours.
The platform's competitive position is output specificity: while generic AI writing tools can rewrite a resume, the Resume Builder produces ATS match scores, keyword gap analysis, formatting compliance checks, and industry-specific section recommendations — giving the candidate a testable confidence level, not just an improved document.
The ATS Problem
The modern hiring pipeline has an invisible gatekeeper. Before a recruiter reads a single resume, before a hiring manager makes a single judgement call, an Applicant Tracking System has already filtered the applicant pool — often eliminating 70–90% of submissions based on automated scoring criteria that the applicants cannot see.
This is not a hypothetical concern. A Harvard Business School study found that ATS systems filter out 27 million qualified Americans per year because their resumes are not optimized for machine parsing. That is not 27 million unqualified candidates. It is 27 million qualified candidates whose professional experience is legible to a human recruiter but not to the parsing rules of a Workday or Taleo implementation.
How ATS Parsing Works
An ATS does not read a resume the way a human does. It parses structured data fields:
- Contact information — extracted and stored (failures here flag the application as incomplete)
- Work experience — job title, company name, dates (parsed for chronology; gaps are flagged)
- Education — degree, institution, graduation year (matched against role requirements)
- Skills section — keyword-extracted and matched against the job's required and preferred skill set
- Keywords throughout — every section is scanned for terms that match the job description's requirement map
The score the ATS assigns is a function of match rate — how many of the job description's required terms, synonyms, and contextual keywords appear in the resume. A candidate with 15 years of directly relevant experience who uses different terminology than the job description will score lower than a candidate with 3 years who mirrored the job description's exact phrasing.
The Information Asymmetry
The hiring organization knows its ATS configuration. The candidate does not. The recruiter knows what keyword threshold triggers a review. The candidate does not. This is a structural information asymmetry — and the Resume Builder resolves it by making the ATS's logic transparent and actionable for the candidate.
Platform Architecture
The platform operates as a three-stage pipeline: ingestion, analysis, and generation.
Stage 1: Ingestion
- Job description ingestion: The user pastes or uploads the JD. The platform parses it for required skills, preferred skills, experience level requirements, industry terminology, and company-specific language signals.
- Resume ingestion: The user uploads their current resume (PDF, DOCX, or plain text). The platform parses it using the same rules an ATS would apply — identifying what an ATS would see, not what a human would read.
Stage 2: Analysis
The analysis layer produces four outputs:
- ATS Match Score (current): What score would this resume receive against this JD in a typical ATS implementation? Scored 0–100 with a breakdown by section.
- Keyword Gap Analysis: Which required and preferred keywords from the JD are absent, present-but-weak (mentioned once, not in context), or strong (in context, backed by evidence) in the current resume?
- Formatting Compliance Check: Is the resume structured in a way that ATS parsers can reliably extract? Common failures: tables (ATS cannot parse table contents reliably), graphics (ignored by parsers), non-standard section headers, unusual fonts.
- Content Gap Assessment: Beyond keywords — are there experience claims in the JD requirements that the current resume doesn't address, even with different terminology?
Stage 3: Generation
The AI rewrite engine produces a tailored resume that:
- Incorporates missing keywords naturally — in context, backed by the candidate's actual experience (never fabricated)
- Restructures content to lead with the most ATS-relevant information
- Reformats any ATS-hostile elements (tables converted to lists, graphics removed)
- Applies industry-standard section naming conventions
- Produces a target ATS Match Score with a delta showing improvement
The output is a new resume document (PDF + DOCX) and an ATS simulation report showing the before/after match score, keyword coverage, and formatting compliance.
Keyword Intelligence Engine
The keyword intelligence engine is the core technical differentiator. It operates at three levels of analysis that most ATS optimization tools never reach.
Level 1: Surface Matching
Does the resume contain the exact terms from the job description? This is what basic ATS optimizers do. It is necessary but insufficient — it catches the most obvious gaps but misses semantic coverage and contextual relevance.
Level 2: Semantic Equivalence
The engine maps semantic equivalents — terms that mean the same thing across different role contexts, industries, and experience levels.
Examples:
- JD: "ML pipelines" → Equivalent: "machine learning workflows", "model training infrastructure", "MLOps"
- JD: "P&L responsibility" → Equivalent: "budget ownership", "financial accountability", "revenue management"
- JD: "cross-functional leadership" → Equivalent: "stakeholder management", "matrixed organization", "executive alignment"
The engine identifies which semantically equivalent terms the candidate uses and, where there is a gap, suggests the preferred industry term for the specific role context.
Level 3: Contextual Strength
A keyword mentioned once in passing is not the same as a keyword supported by a quantified achievement.
- Weak: "Experience with Python" (listed in skills section only)
- Strong: "Built Python-based ETL pipeline processing 2M daily records; reduced processing time from 6 hours to 23 minutes"
The engine scores keyword contextual strength and flags terms that are present but weakly supported — recommending evidence additions that the candidate can make (or confirm) from their actual experience.
ATS Platform Calibration
Different ATS platforms weight and parse differently. Where the platform can infer the likely ATS from company signals (company size, industry, known technology stack), it calibrates the optimization for that platform's known parsing behavior — not just generic best practices.
Market Opportunity & Pricing
The Job Seeker Market
At any given moment, approximately 10–12 million Americans are actively searching for a new job. Globally, the figure is estimated at 200M+ annually. The typical active job seeker submits 50–150 applications per search cycle, tailoring their resume manually for each one — a process that takes 20–40 minutes per application.
That time cost is the primary pain point. The Resume Builder reduces it to under 2 minutes per tailored application.
Buyer Segmentation
| Segment | Characteristics | Willingness to Pay |
|---|---|---|
| Recent graduates | High volume applications; limited experience tailoring | $9–$19/month |
| Mid-career professionals | Role-specific tailoring; ATS sophistication awareness | $29–$49/month |
| Senior professionals | Executive positioning; high stakes applications | $79–$149/month |
| Career changers | Cross-industry translation; significant rewrite need | $29–$79/month |
| Outplacement programs | Institutional purchase for displaced employees | $5–$15/user/month |
Adjacent Revenue Streams
- Career coach partnerships: White-label the platform for career coaching practices
- University career centers: Institutional licensing ($500–$5,000/year per institution)
- Outplacement firms: Volume licensing for displaced workforce programs
- Staffing agencies: Integration API for candidate preparation
Retention Driver
The product's natural retention mechanism is the job search duration. The average active job search lasts 5–6 months. A user who subscribed for Month 1 of their search has high probability of remaining subscribed through Month 5 — the application volume justifies ongoing access. This creates a natural 4–5 month average subscription length per active job search cycle.
That’s the full picture.
More from The Studio
All Papers →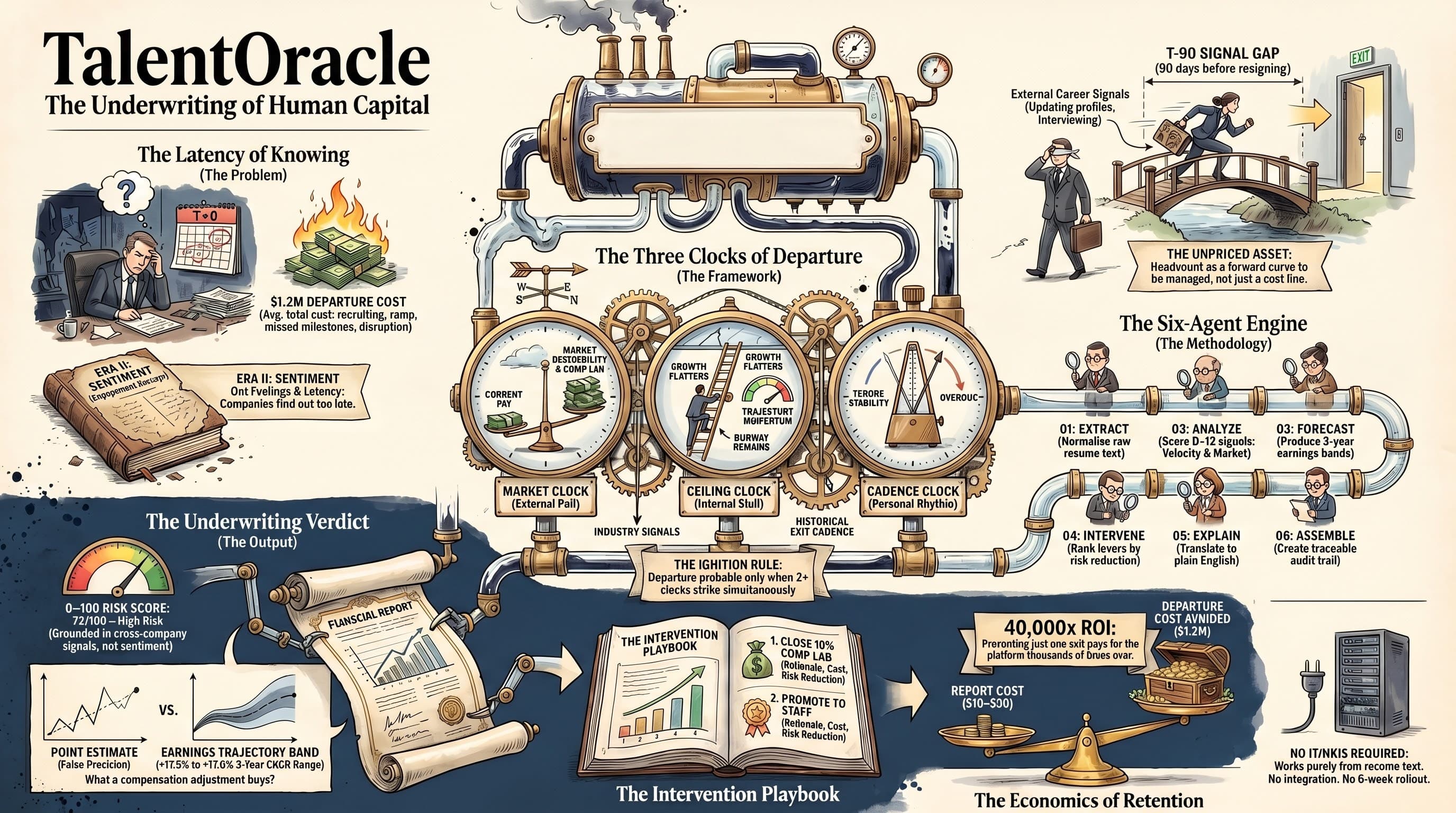
TalentOracle: The Underwriting of Human Capital
The average cost of a senior employee departure is $1.2M when recruiting, ramp, missed milestones, and team disruption are fully loaded. Most companies absorb this cost in silence because they found out too late. TalentOracle is a six-agent AI platform that predicts employee departure 90 days before it happens — using only resume text, with no HRIS integration, no survey, and no manager disclosure required. This paper sets out the Three Clocks of Departure framework, the six-agent engine architecture, the Underwriting Verdict output format, and the economics that make proactive retention the highest-ROI intervention a CHRO can make.

BISO: The Autonomous Security Immune System
BISO — the Bug Immune System — is an autonomous security platform that combines Semgrep, CodeQL, and Snyk scanning with AI-powered vulnerability prediction, autonomous blue-red-judge fix cycles, and semantic bug memory that learns from every outcome. This paper maps the immune system architecture, the self-healing fix loop, the topology-aware prediction model, and the structural case for autonomous AppSec as the successor to reactive vulnerability management.
Want to go deeper?
Discuss this paper with my digital twin.
Ask questions, challenge the framework, explore implications.
Open the Digital Twin