The Token Economy: A First-Principles Playbook for Governing Claude in Production
Why production inference cost is governed by token discipline, not price-per-token — and the four levers that determine your AI program's margin.
“Production inference cost is governed by token discipline, not price-per-token. The firms that compound margin in the AI era will not be those that win the procurement negotiation — they will be those that institutionalize what enters the context window, what those tokens earn while resident, and when they are evicted.”
Paper DNA
Domain
Enterprise AI Economics
Maturity
Build-ready
Market Size
$50B+ global enterprise inference spend projected by 2027
A sub-agent with uncapped recursion and a per-request timestamp invalidating the cache on every call triggered a 243-agent cascade that cost $312,000 in a single night — not because of a technical error, but because the workload had no Charter, no owner, no runaway scenario, and no kill switch.
Four levers govern enterprise Claude economics: model selection (the gating lever), workflow architecture (the largest source of recoverable waste, 3–5× bigger than model choice), data pre-work (a token filtered upstream is paid for once; a token filtered in-context is paid for every call), and prompt literacy (the lever furthest from platform control and closest to the workload's actual users).
The Token Strategy Charter — a 1–3 page planning-time artifact signed before engineering begins — specifies the three scenarios (expected, stretch, runaway), the review topology, the kill criteria, and the quarterly transparency cadence that converts a one-time document into a sustained organizational discipline.
Why Claude Burns Tokens
Claude is the most capable production model family available today, and that capability is precisely why it burns tokens. Understanding why — mechanically, by design — is the precondition for deciding whether you are buying capability you are using or capability you are not.
 The Token Economy — Framework Overview
The Token Economy — Framework Overview
1.1 Long context is an invitation, not an instruction
Claude's 200,000-token context window is a capability the field has, on average, badly misused. The window is an upper bound on what can be in scope for a single call. It is not a recommendation for what should be. The modal enterprise integration treats the window as a filing cabinet: stuff in the policy document, the user's history, the retrieved chunks, the tool descriptions, the conversation transcript, and let the model sort it out.
Every token in the context window has a carrying cost — it is read on every generation, contributes to latency, and competes with other tokens for the model's attention. The model does not know which tokens you intended to be load-bearing. It infers, from position and recency and relevance, what to weight. When the window is full of material that is not earning its place, two things happen simultaneously: the bill goes up, and the output quality goes down. The second effect is the more expensive one and the harder one to see.
The discipline the field needs is to treat the context window as a balance sheet rather than a filing cabinet. Every token is either an asset, a liability, or an expense. Most production stacks have never made the classification, and their bills reflect it.
1.2 Extended thinking trades tokens for correctness
Claude's extended thinking — the model's ability to allocate internal reasoning tokens before producing a user-visible answer — is one of the most economically misunderstood features in the current generation of frontier models. The reflex among cost-conscious teams is to disable it. This is sometimes correct and often expensive in ways that do not appear on the inference invoice.
The mechanical trade is direct: extended thinking spends tokens you pay for in exchange for output quality you also pay for, somewhere else in the system. If the alternative to ten thousand reasoning tokens is a human reviewer correcting a wrong answer, the reasoning tokens are nearly always cheaper. If the alternative is the same answer reached without the reasoning budget — because the task did not require it — the reasoning tokens are pure waste.
The decision is not "thinking on or off." The decision is workload-by-workload: does additional reasoning budget improve the output enough to displace cost elsewhere in the value chain? For legal reasoning, complex financial analysis, multi-step debugging, and structured planning, the answer is reliably yes. For classification, extraction, summarization, and most conversational turns, the answer is reliably no.
1.3 Tool use and agentic patterns multiply calls
Tool use is, for the right workloads, the cheapest possible architecture. Where it goes wrong is the unbounded case. A model that can call tools without a budget, without a depth limit, and without a circuit breaker is a model that can — given the right adversarial input or the wrong malformed response — call them forever.
Agentic patterns multiply calls again. Each agent in a multi-agent system is a full Claude invocation, with its own system prompt, its own context, its own reasoning budget. A "team of five agents" is five times the per-call cost of a single agent, before accounting for the orchestrator's own reasoning and the inter-agent message passing. For some workloads this is the correct architecture. For the modal enterprise workload it is decoration, and the decoration is billed.
1.4 When the consumption is the right trade
Five tests separate the workloads where Claude's consumption profile is correct from the workloads where it is overkill:
- A workload earns frontier-tier consumption when the output quality is itself the product.
- A workload earns extended thinking when the alternative is human review at a higher fully-loaded rate.
- A workload earns long context when the relevant information genuinely cannot be retrieved in chunks.
- A workload earns tool use when the data needed varies by query in ways a static prompt cannot anticipate.
- A workload earns agentic decomposition when the sub-problems are genuinely parallel and individually substantial.
Workloads that fail all five tests should not be running on frontier Claude. The teams that compound margin in this market are the teams that make the classification explicit and revisit it quarterly.
The Pre-Mortem: Planning Before the Build
The dominant posture toward token economics in current enterprise AI practice is reactive. A workload ships. Its bill arrives. Someone is surprised. The posture this paper recommends is the inverse: token strategy is a planning-time discipline, signed before engineering begins.
The Token Strategy Charter
The artifact is the Token Strategy Charter. One to three pages. Produced once per AI-enabled workload, before any code commits. Owned by a named business stakeholder. Co-signed by the platform team and the finance partner. For workloads in regulated domains, co-signed by the risk officer. Revised on a quarterly cadence.
The Charter is not an engineering artifact. It is a commitment artifact — the analog of the documents senior management already uses to approve cloud infrastructure budgets, capital projects, and headcount plans. Its purpose is to make the economics, the risk envelope, and the accountability of an AI-enabled workload legible to the financial and executive functions of the firm, before the workload is built.
The six elements
Purpose and alpha position. What the workload is for, in two paragraphs a board member could read. The business outcome it produces, the baseline it improves against, and the alpha-half-life classification: structural (24+ months), operational (9–18 months), commodity (under 6 months), or expired. A workload whose alpha position cannot be stated has not yet earned its Charter.
Target TRAM cell. The Token Risk Appetite Matrix cell the workload will operate in — cost variance tolerance crossed with output variance tolerance. The cell determines which models are permitted, what agentic depth is authorized, whether extended thinking is enabled, what review topology is required. The cell is chosen by the business owner and the risk officer jointly, not by engineering.
The three scenarios:
- Expected. Steady-state projection. Traffic the workload is built for, token consumption per call as architected, monthly cost at planned volumes. This is the number the finance partner takes back into the budget.
- Stretch. Traffic at two to three times expected. The Charter commits to the operational changes the workload will execute when it crosses into stretch territory.
- Runaway. Traffic or token consumption at ten to twenty times expected — projected explicitly, with a specified kill-switch threshold and a specified escalation path.
A Series C with the Opening Scene's incident on its books, having projected a runaway threshold at five times expected monthly spend with an automatic circuit breaker, would have absorbed a $20,000 incident and a post-mortem the next morning. Instead it absorbed $312,000 and a board call. The cost of projecting the runaway is one meeting.
Review topology. Who reviews this workload's outputs, what they review, when they review, and with what authority — recorded in the Charter so it cannot be silently downgraded by an engineering team optimizing for latency.
Kill criteria. The specific, measurable conditions under which the workload is paused, rolled back, or retired — economic, quality, and strategic triggers, automated where possible, escalated where automation is unsafe.
Transparency cadence. How the Charter's promises are reported back to senior management, in what format, on what schedule. Without scheduled transparency, the Charter decays from a commitment artifact to an internal engineering document within two quarters.
Who signs
Business owner. The executive accountable for the workload's P&L contribution. If no such individual can be named, the workload should not be built.
Platform team lead. Signs for architectural feasibility, cost projection defensibility, and kill-criteria enforceability.
Finance partner. Confirms the expected and stretch scenarios fit the envelope and the runaway threshold is consistent with risk policy.
Risk officer. Functionally mandatory for financial services workloads of any consequence, and mandatory for healthcare.
A firm that approves an AI workload without a Charter is approving a workload without a budget, an owner, or a kill switch — and will, with mathematical certainty, eventually pay the bill for that absence.
Lever One — Model Selection
The first concrete decision the Charter produces is which model runs the workload. Model selection is not the largest source of waste — workflow architecture is, by a factor of three to five. But every downstream lever's economics are conditioned on the model. Model selection is the gating lever, and it is the lever the Charter commits to first.
The three tiers as economic instruments
Claude is offered in three tiers, and the tiers are not "good, better, best." They are three distinct economic instruments with three distinct use profiles. Treating them as a quality ladder produces the wrong answer roughly half the time.
Haiku 4.5 — the distilled tier. Roughly an order of magnitude cheaper per token than Sonnet, fast, capable of substantially more than most teams credit it for. Correct first choice for classification, extraction from structured input, routing in a cascade, the first pass of retrieval re-ranking, and the conversational turns that punctuate longer interactions. For these workloads, Haiku produces output indistinguishable from Sonnet's, at one-tenth the cost.
Sonnet 4.6 — the workhorse. Per-token pricing roughly an order of magnitude above Haiku, capabilities sufficient for the vast majority of enterprise workloads when the prompts are disciplined. Sonnet is the correct default for enterprises that have not yet built the discipline to know which workloads belong on Haiku. It is also the model that runs more workloads than it should.
Opus 4.7 — the frontier instrument. Substantially more expensive than Sonnet, substantially more capable on workloads where capability is the binding constraint. Earns its cost on complex legal reasoning, multi-hop financial analysis requiring auditable inference chains, novel research synthesis, and the production of outputs where a domain expert will sign their name to what the model produced. Running ordinary workloads on Opus is the most expensive form of cargo-culting in current enterprise AI practice.
The cascade — math, not theology
The orthodox advice is to cascade: route through Haiku first, escalate to Sonnet when confidence is low, escalate to Opus when Sonnet's confidence is low. This is presented as obviously correct. It is not obviously correct, and a non-trivial fraction of enterprise cascades currently in production are losing money relative to flat-Sonnet.
The expected cost of a cascade per query:
E[C] = C_Haiku + P(esc_S) · C_Sonnet + P(esc_S) · P(esc_O|S) · C_Opus + C_rework
In a worked example: with a 30% escalation rate to Sonnet, 5% escalation to Opus, and a 4% misroute rate, a cascade saves 36% versus flat-Sonnet. Raise the escalation rate to 60% and the misroute rate to 8%, and the cascade cost becomes identical to flat-Sonnet — and at higher escalation or misroute rates, the cascade loses.
For a non-trivial share of enterprise workloads — particularly those with high complexity variance, drifting input distributions, or weak eval coverage — the cascade is theater. It looks like cost optimization. The teams that win on this lever measure their escalation and misroute rates monthly and revisit the cascade decision quarterly.
Sourcing: Anthropic, Bedrock, Vertex
Anthropic first-party API. Most current feature set — new models appear here first, capabilities like prompt caching, the Batch API, extended thinking, and the Files API arrive here before anywhere else. Default for most enterprise deployments.
Amazon Bedrock. For enterprises with significant AWS commitments or specific data residency requirements. Feature parity lags Anthropic's first-party API by weeks to months for new capabilities.
Google Vertex AI. Analogous trade-offs for GCP-committed enterprises.
The economic logic of the four levers is identical across sourcing paths. The lever you pull is the lever you pull regardless of where the tokens come from.
Lever Two — Workflow Architecture
Model selection sets the price per token. Workflow architecture determines how many tokens you spend per task. The first lever caps the unit cost. The second governs the quantity — and quantity, not unit cost, is where the modal enterprise Claude bill is built and broken.
The Orchestration Multiplier
The Orchestration Multiplier (OM) is the ratio of total tokens consumed per user-visible action to the tokens that would have been consumed by a single, well-prompted Claude call accomplishing the same task with native tool use.
- A single tool-using call has an OM of 1.0 by definition.
- A two-agent supervisor-worker pattern typically lands at 2.5–3.5×.
- A three-tier agentic decomposition with parallel workers and a synthesis step lands at 6–10×.
- The Opening Scene's incident, at peak recursion, had an OM somewhere between 200 and 300.
The modal enterprise Claude deployment has an aggregate OM of 4–6×, and an OM of 1.5–2× is achievable on the same workload portfolio with no loss of capability. That delta — three turns of the multiplier — is the largest single source of recoverable waste in current enterprise stacks. It is also invisible to every cost dashboard that reports tokens per call rather than tokens per user action.
Most agentic workloads should be a single call
Native tool use accomplishes most of what enterprise teams build multi-agent systems to accomplish, at one-fifth to one-tenth the token cost and with measurably higher reliability.
Multi-agent decomposition genuinely earns its OM when three conditions are met:
- Parallel and substantial sub-problems. Three workers analyzing three different documents and reporting independently is real parallelism. Three workers each calling the same tool with slightly different parameters is parallelism in name only.
- Synthesis the workers cannot do. If the supervisor's role is to aggregate worker outputs requiring reasoning over them as a set, the supervisor earns its cost. If the supervisor is just routing, it is overhead.
- Stable decomposition. Workloads where the right decomposition varies query-by-query produce the runaway-recursion risk profile the Opening Scene illustrated.
Roughly 70% of production agentic workflows fail at least two of these conditions. This is the recoverable waste pool, and it is large.
The Cache Cliff
The Cache Cliff is the QPS threshold below which prompt caching is net-negative despite appearing in every cost-optimization checklist as a default-on optimization.
Caching breaks even at roughly 3–5 sustained QPS on a given system prompt (assuming a five-minute TTL). A substantial fraction of enterprise workloads sit below this threshold. They have caching enabled because it looks legible to finance — not because anyone ran the break-even.
Worse: a system prompt that contains a per-request timestamp, a user identifier, or any variable element invalidates the cache on every call — infinite writes, zero hits, pure premium paid for no benefit. This anti-pattern is present in roughly one-third of enterprise Claude deployments that have caching enabled.
The Eviction Discipline
Multi-turn workflows accumulate context. Each turn's input becomes part of the next turn's context. Each tool call's result joins the working set. Each retrieval result enters and, in most stacks, never leaves. By turn ten of an extended conversation, the working context can carry 40,000–80,000 tokens of accumulated history — most of which is no longer earning its place.
The Eviction Discipline specifies, per workflow: a turn cap, a relevance score, a tool-result truncation rule, and an explicit summarization trigger. A workflow with no eviction discipline consumes, by turn ten, roughly five to eight times the tokens of the same workflow with eviction at turn five and summarization at turn seven. Output quality is, in most cases, better with eviction — because the model is not weighting thirty thousand tokens of stale conversational history against the current user input.
The Fifth Lever — Human Judgment
The four levers control how much the model costs to run. The Fifth Lever controls which of the model's outputs propagate into the world without a human ratifying them. It has a measurable cost, a measurable return, and a substitution structure with the other four — and it is where control, governance, and ethics converge into a single decision.
The four questions
A workload's Review Topology answers four questions:
Who reviews. The qualification level of the reviewer, named explicitly. A licensed clinician for clinical outputs. A credit officer with specified delegated authority for credit decisions. "Anyone" is not an answer. "Subject-matter experts as appropriate" is not an answer.
What they review. One of four patterns: every output (100% pre-issue review), statistical sample (1–10% post-issue with documented sampling strategy), exceptions (model-flagged low-confidence outputs plus a stratified sample), or incidents (post-hoc review triggered by complaint or failure).
When they review. Pre-issue, post-issue pre-action, post-action, or post-incident only. The timing decision is the largest single driver of latency cost, and the lever engineering teams are most often tempted to silently downgrade.
With what authority. Veto (reviewer can stop the output), override (reviewer can modify with logging), advisory (reviewer flags concerns but output proceeds), or audit (reviewer documents post-hoc without altering the historical decision).
Review economics
Review earns its place when:
p · V > C_R + L_R
Where p is the probability the model errs on this class of workload, V is the value of catching the error before it propagates, C_R is the fully-loaded reviewer cost per case, and L_R is the latency cost incurred by the review step.
The expensive insight: p is not constant. It depends on which model the Charter authorized, how much the workload spent on data pre-work, how well-calibrated the prompt is, and how disciplined the workflow architecture is. The fastest way to reduce review costs is rarely to optimize review. It is to invest upstream in the four levers that reduce p.
The ethical line
Three categories of decision, treated differently:
Adverse decisions about identified individuals belong with accountable humans regardless of model capability. A loan denial, a benefit termination, a clinical action with material consequences — these are decisions where the affected individual must have an accountable human to whom appeal can be made. The model may propose, may score, may summarize the case. The decision is human, and the human is named. This is not a function of current model accuracy. It is a function of what accountability requires.
Decisions that aggregate over populations can be model-driven with human governance of the policy — pricing algorithms, fraud detection thresholds, recommendation systems.
Decisions whose error mode is erosion of trust sit in a middle zone. A wealth management firm whose clients believe they are receiving human-authored communications has made a promise the Charter must honor.
Explicitly naming the category each workload belongs to — in the Charter, before engineering begins — is the discipline that prevents the firm from accidentally crossing ethical lines it would not have crossed deliberately. The Opening Scene's fintech did not deliberately decide to recurse 243 times. It accidentally decided, by not deciding.
Lever Three — Data Pre-Work
The Fifth Lever determines which model outputs propagate into the world. This lever determines what enters the model's context window in the first place — and the firms that have built Charter discipline find, when they audit their stacks, that the largest remaining efficiency gains live here.
A token filtered upstream — at ingestion, in the index, in the retrieval ranker, in the chunker — is paid for once. A token filtered in-context, by the model itself, is paid for every time the workload runs. Across a high-traffic workload running ten thousand calls a day for a year, the difference between filtering once and filtering 3.65 million times is the difference between a one-time engineering investment and a recurring inference line item that scales with adoption.
The four upstream interventions
Ingestion-time filtering. Documents and data entering the retrieval system are filtered for relevance, quality, recency, and authority before they are indexed at all. Stale policy documents, superseded contract versions, low-quality auto-generated content, and documents outside the workload's authorized scope are excluded at the source. A document never indexed is never retrieved, never chunked, never tokenized, and never paid for.
Index-time structure. The index is structured to make filtering at query time fast and cheap. Metadata fields indexed. Vector embeddings at appropriate chunk granularity. Hierarchical structure preserved.
Retrieval-time ranking and filtering. At query time, the system returns more candidates than working context will admit and ranks and filters down. This is the intervention point most RAG optimization discussions concentrate on — and the one with the least leverage relative to the two upstream of it.
Chunk shape and size. The unit of context retrieved determines how much working context the workload consumes per relevant fact. Chunks too large carry passenger tokens. Chunks too small fragment the reasoning context. Most enterprise RAG stacks have never tuned chunk shape against the actual workload they serve.
The compound math
Consider a workload that retrieves, on average, eight chunks per query, each averaging 400 tokens. Without ingestion-time filtering, roughly 40% of those chunks are passengers. The workload runs 5,000 queries per day.
Passenger tokens per day: 8 × 400 × 0.40 × 5,000 = 6,400,000
Roughly 1.9 billion per year.
A one-time ingestion filtering project — three engineer-months of work, a documented filter policy, automated re-application as documents enter the corpus — eliminates roughly 70% of the passenger volume. The recurring saving, at Sonnet pricing, is on the order of several hundred thousand dollars per year for this single workload. The fixed cost of the project pays back inside a quarter.
The Reasoning–Retrieval Frontier
Reasoning tokens and retrieval tokens are partially substitutable. For a substantial class of enterprise questions — particularly internal questions about general business or technical knowledge that does not change quarter to quarter — retrieval is overhead the workload is paying for to access information the model already has.
Measure the accuracy of the workload's questions answered by extended thinking alone, against the accuracy with retrieval, against the cost of each approach. Roughly 20–30% of enterprise RAG workloads are operating in this category and have not measured the alternative. The counter-position: for workloads against proprietary data, against rapidly changing data, or against data with regulatory provenance requirements, retrieval is not optional.
Lever Four — Prompt Literacy
The right data work upstream determines what enters the model's context window. This lever determines whether the humans on either end of the system know how to communicate with what is in that window. It is the lever that operates furthest from the platform team's direct control and closest to the workload's actual users.
The Prompt Literacy Ladder
Level One — Consumer. Types natural-language questions, reads natural-language answers. No model of the model. Safe for single-turn Q&A against well-engineered system prompts.
Level Two — Structured user. Understands prompts have anatomy — context, instruction, examples, constraints, format — and structures inputs deliberately. Knows when to provide examples and when not to. Training cost to move up: roughly four hours of structured exposure with hands-on practice.
Level Three — Configurator. Writes effective system prompts, defines tool descriptions, structures retrieval grounding, configures conversational surfaces to produce workloads other users will consume. Training cost to Level Four: three to six months on real production prompts with senior review.
Level Four — Prompt engineer. Designs prompt architectures for production. Understands caching invalidation patterns. Debugs prompts that pass tests and fail in production. Writes evals that catch the failure modes their prompts are most prone to.
Level Five — Prompt architect. Designs prompt strategy across the workload portfolio. Defines the patterns the organization uses. Owns the Prompt-as-Code discipline. Represents prompt design in Charter reviews. Population per enterprise: typically one to three.
Prompt-as-Code
System prompts grow. Tool descriptions accumulate. Grounding source lists expand as new content gets indexed. Conversational scaffolding gets added in response to specific user complaints. None of this is captured in the version control discipline most enterprises apply to their application code.
The discipline this paper recommends is Prompt-as-Code: prompts and configuration surfaces are versioned, diffed, reviewed, canaried, and rolled back with the same discipline applied to application code. Eval gates run on prompt changes the same way regression tests run on code changes. This is, in auditing experience, the single most absent discipline in enterprise AI programs.
The contrarian case for training over hiring
The orthodox response to AI program underperformance is to hire more platform engineers, more prompt engineers, more AI specialists. For a substantial fraction of mid-sized enterprises, this is a wrong-direction investment.
A $200,000 training program that moves 500 users from Level One to Level Two produces measurable per-interaction quality improvements across hundreds of thousands of interactions per quarter. The same $200,000 spent on a single engineer-year produces improvements on a handful of workloads. The math frequently favors training the population over hiring more specialists.
User education that actually works
Training that works has three properties:
- Anchored in the user's actual job. A salesperson learns prompt engineering as it applies to drafting client communications, summarizing call transcripts, analyzing pipeline data — using the actual systems and content they work with daily.
- Paired with feedback loops. The user produces a prompt, sees the output, and receives structured feedback. Without feedback, users learn idiosyncratic and often counterproductive habits.
- Explicit about when not to use AI. The most expensive prompt is the one that produces a bad answer the user trusts. Training that teaches users to recognize the workloads their AI tools are suited for pays back in errors prevented, not just productivity gained.
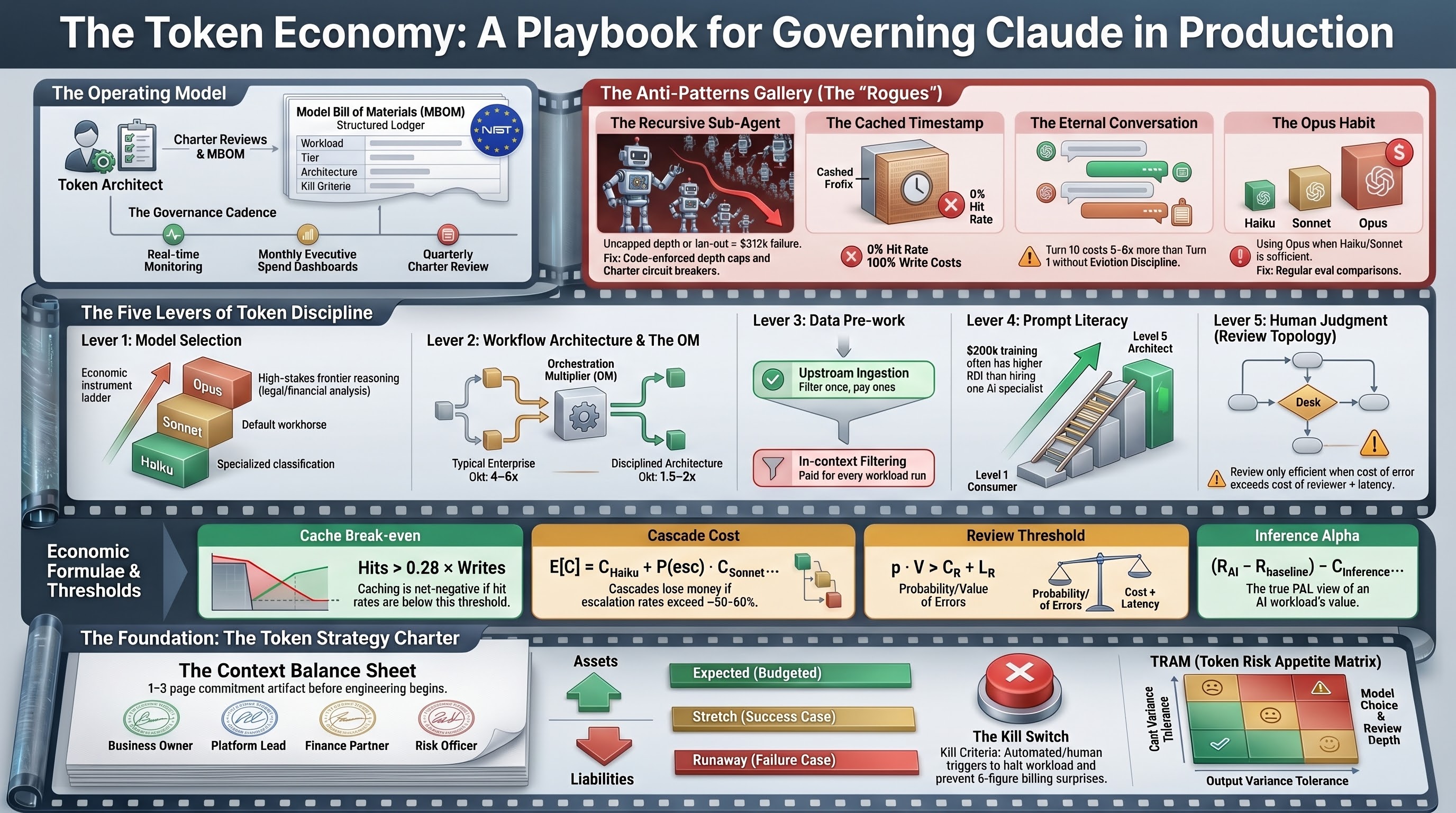
The Operating Model
A Charter signed once is a document. A Charter reviewed quarterly, against a ledger of realized outcomes, by named roles on a defined cadence, is a discipline. The difference is the operating model — the institutional machinery that converts the planning posture this paper has argued for into a sustained organizational capability.
The Token Architect
A new staff-level discipline, named explicitly because the absence of a name is part of why it has not yet emerged in most enterprises. The Token Architect owns the operating model for AI economics across the workload portfolio.
Charter review. For every new AI-enabled workload before engineering begins. The Token Architect is not the approver — the business owner, finance partner, and risk officer are — but the technical conscience of the review.
Model Bill of Materials (MBOM). Every workload in production, its model tier, its workflow architecture, its data pre-work posture, its prompt literacy requirement, its review topology, its kill criteria, and its current TRAM cell. Updated when any of these change. Surfaced quarterly to senior management.
Exception governance. When a workload needs to operate outside its Charter — higher agentic depth, a different model tier, a relaxed review topology — the Token Architect reviews the exception, documents the rationale, and determines whether a Charter revision is required or the exception is time-bounded and self-correcting.
The seniority of the role matters. The Token Architect must have the standing to push back on engineering decisions that produce hidden token costs, to require Charter revisions when workloads drift from their approved configuration, and to surface economic variance to senior management in a format that produces organizational response.
The cadence
Daily. Automated monitoring surfaces any workload whose token consumption has crossed a predefined threshold relative to its Charter's expected scenario. Alerts are operational, not finance — they go to the on-call engineer, not the monthly billing review.
Weekly. Token Architect reviews accumulated exceptions, escalates patterns rather than individual incidents.
Monthly. Per-workload Alpha-net per dollar of inference spend, reported against Charter projections. Variances above a threshold require a written explanation from the business owner and platform team lead.
Quarterly. Charter review cycle. Every production workload: what was planned, what was spent and produced, what was learned, what changes to the Charter the platform team and business owner jointly recommend. The discipline is sustained by the visibility.
Annually. The operating model itself is reviewed. The meta-discipline that prevents the operating model from ossifying into bureaucracy.
The Anti-Patterns Gallery & The Frontier
Ten rogues. Each is named, with symptom, root cause, telemetry fingerprint, and fix. Each is also a Charter discipline failure as much as a technical failure — and the Charter is the upstream fix.
 The Token Economy — Anti-Patterns & Governance Reference
The Token Economy — Anti-Patterns & Governance Reference
The Ten Anti-Patterns
1. The Recursive Sub-Agent. Symptom: token consumption spikes 5–50× without proportional traffic increase. Root cause: agentic workflow with uncapped recursion depth or fan-out. The Opening Scene's $312,000 night. Fix: depth and fan-out caps enforced in code; circuit breaker at the Charter's runaway threshold; automated kill requiring human authorization to resume.
2. The Cached Timestamp. Symptom: cache write costs accumulate, cache hit rate stays at zero. Root cause: variable content embedded in a cached prefix, invalidating the cache on every call. Fingerprint: cache write count equals call count; cache read count near zero. Fix: audit cached prefixes for variable content; move variable elements out of the cached region.
3. The Phantom RAG. Symptom: retrieval-augmented workload performs no better than the same workload without retrieval. Root cause: the workload's questions are answerable from the model's parametric knowledge; retrieval adds tokens without adding correctness. Fix: run the A/B test; migrate qualifying workloads to extended thinking without retrieval.
4. The Eternal Conversation. Symptom: per-call token consumption grows monotonically with conversation length. Root cause: no eviction discipline; full conversation history carried in working context indefinitely. By turn ten, consuming 5–8× the tokens of turn one. Fix: implement eviction policy — turn cap with summarization, relevance scoring, explicit reset triggers.
5. The Opus Habit. Symptom: workloads running on Opus that produce outputs indistinguishable from Sonnet outputs on the same inputs. Root cause: tier was chosen at deployment time, never revisited; no eval comparison against cheaper tier. Fix: run the eval; downgrade where indistinguishable; document the decision in the next Charter review.
6. The Unbounded System Prompt. Symptom: system prompt has grown to 15,000+ tokens through accumulation. Root cause: no Prompt-as-Code discipline; prompts edited ad-hoc without review or eval gating. Fix: implement Prompt-as-Code; decompose accumulated instructions into Skills or analogous deferred-context mechanisms.
7. The Cascade That Doesn't. Symptom: Haiku-Sonnet-Opus cascade in production, but actual savings versus flat-Sonnet are zero or negative. Root cause: escalation rates higher than the cascade was designed for, or misroute costs higher than projected. Fix: measure the escalation and misroute rates; run the break-even math; switch to flat-Sonnet if the cascade is not earning its place.
8. The Ungoverned Tool. Symptom: tool calls per user-action exceed projection. Root cause: tool definitions are unclear; the model re-fetches the same information because the prompt does not specify retention. Fingerprint: same tool called with the same parameters multiple times in a single workflow trace. Fix: clarify tool descriptions; add prompt instructions about retention.
9. The Silent Downgrade. Symptom: production workload's review topology has weakened from Charter specification. Root cause: engineering team facing latency or throughput pressure silently relaxed the review step. Fix: governance dashboard surfaces the variance; Token Architect escalates; either the topology is restored or the Charter is formally revised with risk officer signature.
10. The Orphaned Workload. Symptom: production workload consuming non-trivial tokens with no named business owner, no recent review, no documented current purpose. Root cause: workload's original sponsor moved on; no one explicitly inherited ownership. Fix: identify the workload's current consumers; assign an owner or retire the workload.
The Frontier — Three Calibrated Predictions
Prediction one. By end of 2027, the per-token price of the workhorse tier will have fallen sufficiently that more than half of currently-running cascade architectures will no longer be economically justified versus flat-mid-tier deployment.
Prediction two. By end of 2027, agentic decomposition will have inverted its current economic profile in at least one direction: either sub-agents become substantially cheaper through specialized small models, or the workhorse tier's single-call capability will have advanced sufficiently that the current 70% of agentic workloads that should be single calls becomes 90%.
Prediction three. By end of 2028, regulatory frameworks in financial services and healthcare in at least two major jurisdictions will require some form of context lineage documentation, making the MBOM-and-Charter discipline either explicit regulatory requirement or de facto industry standard.
These predictions are commitments to falsification criteria, made publicly so the paper's framework can be evaluated against subsequent reality. A paper that does not commit to falsifiable predictions is a paper that cannot be wrong, which means it cannot have been right.
The fintech in the Opening Scene did not fail because of a malformed JSON. It failed because a four-million-dollar inference line item had no Charter, no owner, no runaway scenario, no kill criteria, and no quarterly review. The technical failure was downstream of the governance gap. The governance gap was downstream of a posture. The posture begins changing with the Charter — and the Charter begins with the decision to write it this quarter, rather than after the next incident makes it unavoidable.
That’s the full picture.
More from The Studio
All Papers →
BLACKBOX: The Flight Recorder for AI Agents
When an AI agent makes a wrong decision, enterprises need to answer three questions: what exactly happened, in what order, and can the record be trusted? BLACKBOX provides the infrastructure layer that makes all three answerable. Every event — reasoning step, tool call, output, fault — is sealed into a SHA-256 hash chain. Any alteration to any stored event breaks the chain. Any run can be replayed verbatim. This paper documents the architecture, the three instrumentation paths, the phases completed, and the enterprise case for treating AI agent observability as an insurance requirement, not a nice-to-have.

Combating Latency & Hallucination in Agentic Enterprise SaaS
Latency and hallucination are not bugs to be patched late in the cycle — they are first-class design constraints. This PM's playbook maps every failure mode, engineering mitigation, governance gate, and stakeholder conversation needed to ship reliable agentic systems in regulated enterprises.
Want to go deeper?
Discuss this paper with my digital twin.
Ask questions, challenge the framework, explore implications.
Open the Digital Twin