Combating Latency & Hallucination in Agentic Enterprise SaaS
A Project Manager's Playbook for Designing, Building, and Deploying Reliable AI Agents in Regulated Enterprises.
“Reliable agentic systems are not the result of better prompts. They are the result of a project management discipline that makes latency and accuracy testable, observable, and owned.”
Paper DNA
Domain
Agentic AI Production Engineering
Maturity
Build-ready
Market Size
Every enterprise deploying AI agents at scale
Latency and hallucination are first-class design constraints, not post-launch patches. A PM who defers them to an optimization phase will not ship a system that a regulated enterprise will trust.
The majority of production hallucinations are retrieval failures, not generation failures. Invest in chunking strategy, embedding selection, and reranking before touching the prompt — that is where the leverage is.
Every agent hop is a compounding tax on both latency and accuracy. Most agentic systems are over-graphed. Challenge any architecture with more than 3–4 user-facing hops and ask: can two of these be merged into one?
Executive Summary
Enterprise SaaS buyers have moved past the demo phase. They have seen the magic and now ask the harder question: can this system be trusted to act on our behalf at scale, under audit, and in real time?
For agentic systems — where language models plan, call tools, retrieve data, and chain decisions — two failure modes dominate every other concern. Responses arrive too slowly to be useful, or they arrive confidently wrong. Either failure, encountered twice by a senior user, ends the pilot.
 The Agentic Enterprise: A PM's Playbook for Reliable AI Operations
The Agentic Enterprise: A PM's Playbook for Reliable AI Operations
Five takeaways that govern everything that follows:
- Treat latency budgets and accuracy thresholds as contractual requirements, not aspirational targets. Define them per use case, per agent hop, and per user persona before development starts.
- Invest in evaluation infrastructure before agent capability. A team without a regression suite, golden dataset, and hallucination taxonomy cannot defend its system in production.
- Architect for grounding, not eloquence. Retrieval quality, tool calling discipline, and structured outputs eliminate the majority of hallucinations that fluent models otherwise generate.
- Reduce hops aggressively. Every additional model call, tool invocation, or agent handoff compounds both latency and the probability of error. Most agentic systems are over-graphed.
- Communicate residual risk in the language of the audience. Engineers need defect classes; the business needs SLAs and decision rights; the board needs alignment with the firm's model risk policy.
Bottom line: Reliable agentic systems are not the result of better prompts. They are the result of a project management discipline that makes latency and accuracy testable, observable, and owned. The technology is necessary but not sufficient. The operating model is the differentiator.
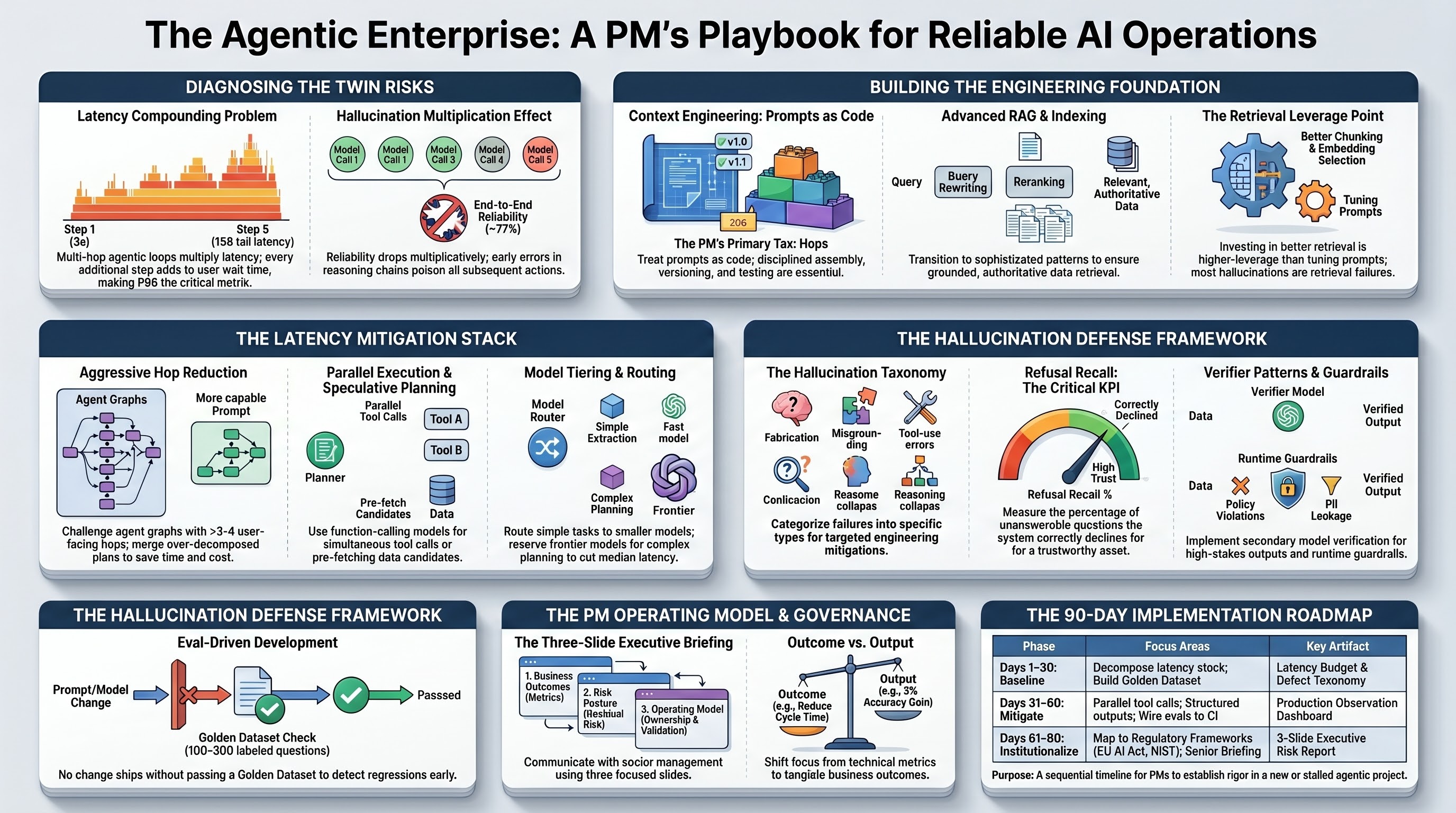
The Twin Risks in Agentic Enterprise AI
A traditional chatbot makes one inference per user turn. The latency is the model latency; the accuracy is the model accuracy. An agentic system is structurally different. It plans, decomposes, retrieves, calls tools, observes, replans, and synthesises. A single user request may trigger ten to fifty model calls and tool invocations behind the scenes.
Two mathematical realities govern these systems and every PM working in this space should internalize them.
The Latency Compounding Problem
If each step in a five-step agent loop takes three seconds, the user waits fifteen seconds. If the planner decides on seven steps, the user waits twenty-one. Network jitter, tool timeouts, and retries push the tail latency far beyond the mean. A system with a 4-second median can have a 30-second 99th percentile — and the 99th percentile is what your users remember.
The Hallucination Compounding Problem
If each model call is 95% accurate on a given task, a five-call chain is approximately 77% accurate end-to-end, assuming independent errors. Errors are rarely independent — a misretrieved fact poisons every downstream step — so the real number is worse. Reliability does not compose additively; it compounds multiplicatively, and the multiplication is hostile.
The Implication for the PM
Every agent hop you allow into the architecture is a tax on both latency and accuracy. Your job is not to maximise the elegance of the agent graph. It is to minimise the number of hops needed to deliver the business outcome, and to make every remaining hop verifiable.
What Enterprise Buyers Actually Require
In regulated industries — banks, insurers, asset managers — three requirements dominate procurement and security review:
| Buyer Requirement | Latency Implication | Hallucination Implication |
|---|---|---|
| Predictable response time under load | P95 and P99 latency targets in the contract | Caching cannot mask wrong answers |
| Auditable reasoning and citations | Logging adds overhead that must be budgeted | Every claim must trace to a source document |
| Bounded autonomy with human override | Approval gates introduce wait states | The model must surface uncertainty for human override |
Technical Foundation — From Chatbots to Agentic Stacks
The PM needs a shared vocabulary for what agentic systems are made of. Five building blocks are universal across enterprise deployments.
From Chatbot to Agent: The Architectural Shift
| Dimension | Chatbot | Agentic System |
|---|---|---|
| Failure surface | Prompt + model | Prompt + model + retrieval + tools + memory + state + guardrails |
| Latency profile | Single inference | Multi-hop, compounding, tool-bound tail |
| Dominant error mode | Generation quality | Retrieval failure, tool misuse, plan drift |
| Governance posture | Model risk only | Model risk + data lineage + tool authorization + audit trail |
Most agentic project failures are not language model problems. They are integration problems, data problems, and indexing problems wearing a language model costume. The PM who diagnoses every issue as a prompt issue will miss the dominant failure mode.
Context Engineering: Prompts as Code
A system prompt is code in the architectural sense. It is loaded at runtime, executed by the model, and produces outputs that affect downstream systems. Three rules cover ninety percent of the discipline: every prompt is versioned in source control; every prompt change runs through the eval suite before deployment; every production prompt has a named owner and a changelog.
Context budgeting matters. Long contexts cost latency, money per token, and accuracy through the lost-in-the-middle effect, where important information placed in the middle of a long context is attended to less reliably. The PM should require active context budgeting — each agent step has an explicit input token target — and should view unbounded context growth as a defect.
RAG Architecture: From Naive to Agentic
In the majority of production deployments, most user-visible hallucinations are retrieval failures rather than generation failures. When the right context is in the model's input, the model usually answers correctly. When it is not, the model fabricates fluently.
The advanced RAG patterns — query rewriting, multi-query expansion, reranking, chain-of-verification, agentic RAG, and graph RAG — address different failure modes. The choice of pattern should follow the measured failure mode, not engineering enthusiasm. Adding chain-of-verification to a system that does not yet have a measured groundedness problem is over-engineering that costs latency and adds failure modes.
Anatomy of Latency in Agentic Systems
Before mitigating latency, the PM must be able to decompose it. The most common project failure is treating latency as a single number rather than a stack of contributing components.
The Latency Stack
| Layer | Typical Contribution | Primary Levers |
|---|---|---|
| Network and client round-trip | 100–400 ms per call | Edge deployment, connection pooling |
| Authentication and routing | 20–150 ms | Token caching, gateway co-location |
| Retrieval (vector search, SQL, API) | 100–800 ms per retrieval | Index tuning, parallelism, pre-computation |
| Model inference (per call) | 500 ms – 8 s | Model selection, streaming, output length caps |
| Tool execution (external APIs) | 200 ms – 10 s | Async parallel calls, timeouts, circuit breakers |
| Agent loop orchestration | Multiplicative across hops | Hop reduction, speculative planning |
| Post-processing and validation | 50–500 ms | Schema-first outputs, lightweight validators |
Why Median Latency Lies
Enterprise users do not experience the median. They experience the worst case they happened to hit yesterday in front of their boss. A system with a 4-second median and a 25-second P99 will be perceived as broken. PMs must require teams to report P50, P95, and P99 separately, and to set acceptance criteria against the tail rather than the average.
The Hidden Cost of Streaming
Streaming partial tokens reduces perceived latency dramatically — sometimes by 60–80% in user testing — even when total wall time is unchanged. But streaming complicates validation (you cannot easily reject a partially streamed hallucination) and interacts poorly with tool-calling architectures where the user must wait for tool execution before any visible output appears.
Diagnostic question for engineering: Where in our trace is the time actually being spent? If the team cannot show a flame graph or span breakdown for a representative request within an hour of asking, the system is not yet observable enough to optimise.
Anatomy of Hallucination in Agentic Systems
Hallucination is an unhelpful word because it bundles distinct failure modes together. Treating them as one problem leads to one-size-fits-all mitigations that do not work. The PM's first task is to demand a taxonomy from the engineering team and require that every defect be categorised by class.
A Working Taxonomy of Hallucination
| Class | Description | Most Effective Mitigation |
|---|---|---|
| Fabrication | Confident invention of facts, entities, or citations not present in any source | Strict RAG with citation enforcement; refuse-to-answer thresholds |
| Misgrounding | Real source data exists but the model misreads or misattributes it | Better chunking, reranking, chain-of-verification |
| Specification drift | Output violates stated constraint (wrong format, missed instruction) | Structured outputs, schema validation, system-prompt audits |
| Tool-use error | Model selects wrong tool, passes malformed arguments, or hallucinates a non-existent tool | Tighter tool descriptions, allowed-tool whitelists per state |
| Stale-context error | Model uses cached or outdated context where fresh data was required | Cache invalidation policies, freshness signals in retrieval |
| Reasoning collapse | Multi-step plan loses coherence; later steps contradict earlier ones | Shorter plans, explicit state passing, verifier agents |
| Sycophancy | Model agrees with incorrect user premise rather than correcting it | System prompts with explicit override behaviour; calibration testing |
The Fluency Trap
Large language models are optimised to produce fluent, plausible text. Fluency is correlated with confidence in human perception, which means a confidently delivered wrong answer is more dangerous than an obviously confused one.
The single most useful KPI you can introduce: Refusal recall — the percentage of unanswerable questions for which the agent correctly declines rather than fabricating. A system with 95% accuracy on answerable questions but 10% refusal recall is a liability. A system with 85% accuracy and 90% refusal recall is shippable.
Engineering the Solution: Latency Mitigations
Latency mitigation in agentic systems is fundamentally about doing less work, doing it in parallel, or doing it speculatively. The following patterns, applied in combination, can reduce P95 latency by 50–80% against a naive baseline.
Model Routing and Tiering
Not every step requires the most capable model. A planner step may benefit from a frontier model; a simple extraction step can use a smaller, faster, cheaper model. A well-designed router can cut median latency in half while preserving end-to-end quality.
Parallel Tool Calls and Speculative Execution
Modern function-calling models can emit multiple tool calls in a single turn. Executing them in parallel can collapse a four-second sequence into a one-second burst. Speculative execution goes further: while the planner is deciding, the system pre-fetches the most likely candidates so that whichever path the planner chooses, the data is already warm.
Hop Reduction and Graph Compression
The single most effective latency mitigation in most agentic systems is reducing the number of hops. A common anti-pattern is the over-decomposed plan, where the agent breaks a simple task into ten micro-steps because the framework encourages it. PMs should challenge any agent graph with more than 3–4 user-facing hops.
Output Length Discipline
Token generation is the dominant cost in most inference workloads, scaling linearly with output length. A response twice as long takes twice as long to generate. Treat verbose outputs as a defect, not a feature.
| Mitigation | Typical P95 Reduction | Risk Introduced |
|---|---|---|
| Model routing | 20–40% | Routing errors; eval surface grows |
| Exact caching | 5–15% | Stale answers if invalidation fails |
| Parallel tool calls | 20–50% | Cost multiplication; rate-limit exposure |
| Hop reduction | 30–60% | More complex prompts; harder to debug |
| Streaming | Perceived 40–70% | Harder to validate before display |
| Output length caps | 10–30% | Truncated answers if cap is too aggressive |
Engineering the Solution: Hallucination Mitigations
Hallucination mitigations fall into four families: grounding, structure, verification, and abstention. A mature agentic system uses all four. The PM's role is to ensure no family is neglected — a common failure is to over-invest in retrieval and under-invest in abstention.
Grounding Through Retrieval
Effective grounding requires attention to chunking strategy, embedding model selection, reranking, hybrid lexical-semantic search, and metadata filtering. PMs should require a retrieval evaluation harness that measures recall@k against a labelled question set — separately from end-to-end accuracy. A model cannot answer correctly from documents that were not retrieved, and a retrieval miss is a hallucination cause that no prompt engineering will fix.
Structured Outputs and Schema Enforcement
Free-form text outputs are the highest-variance interface a model can offer. Structured outputs — JSON conforming to a schema, typed fields — dramatically reduce specification drift and enable downstream validation. Modern models support constrained decoding that guarantees schema conformance at the token level.
Tool Calling Discipline
Tools are how agents touch the real world, and the quality of tool descriptions directly determines how often the model selects the right one. Common failure patterns include vague tool descriptions, overlapping tool semantics, and unbounded tool surfaces that present the model with too many options. A useful constraint: limit the tools available at any given agent state.
Confidence Calibration and Abstention
The hardest behaviour to engineer into an agentic system is the willingness to say "I do not know" when the answer is not available. This requires explicit prompting, runtime confidence signals derived from retrieval scores, log probabilities, or verifier disagreement. A system that refuses well is a system the business can trust.
PM checklist for hallucination mitigation: Retrieval evaluated separately from generation. Outputs structured wherever possible. Tools described precisely and scoped per state. Verifiers deployed on high-risk outputs. Abstention measured as a first-class KPI. Guardrails evaluated for false positives. If any of these is missing, the system is not production-ready regardless of demo quality.
The PM Lens — Three Conversations That Determine Outcomes
Working with Developers
Before development begins, the PM should drive agreement on five contracts: latency budget per use case decomposed by component; accuracy and refusal thresholds against a defined evaluation set; a defect taxonomy that maps every failure to a class and a mitigation; observability requirements including per-request tracing; and a rollback path executable within a defined window.
The standup conversation that matters: What does the latest eval run show? What regressed? What new failure mode appeared in production yesterday and where does it fit in the taxonomy? What is our P95 latency trend? If the team cannot answer from telemetry rather than from memory, the observability investment is insufficient.
Working with Business Stakeholders
The honest framing of capability is: what the system can do today, what it can do with two more sprints, and what is genuinely outside the envelope. PMs should resist the pressure to commit to the third category to win sponsorship.
Grounding latency expectations in user behaviour: how long is a customer willing to wait on a chat, on an internal copilot, on a batch report? "Under three seconds for first token, under eight seconds for full response" is a target you can design against. "As fast as possible" is not.
Working with Senior Management
Senior management care about three things: business outcome, residual risk, and alignment with the firm's governance posture.
The three-slide briefing:
- Business outcome — what the system does for the business, in the metrics they already track
- Risk posture — what could go wrong, what controls exist, what residual risk remains, how it compares to risk appetite
- Operating model — who owns the system, who validates it, how incidents are escalated
The right framing for hallucination is not "our system is 98% accurate" but "in the highest-risk use cases we route through human review, which has added two hours to average turnaround but eliminated the three categories of customer complaint we saw in pilot."
| Regulatory Framework | Relevance | Typical PM Artifact |
|---|---|---|
| SR 11-7 (US Federal Reserve) | Model risk management lifecycle | Model inventory; validation report; monitoring plan |
| NIST AI RMF | Govern, Map, Measure, Manage functions | AI risk register; control mapping |
| EU AI Act | Risk classification for high-risk AI | Conformity assessment; technical documentation |
| BCBS 239 | Data aggregation where agents touch reporting | Data lineage; aggregation accuracy testing |
Governance, Metrics & the Operating Model
A reliable agentic system is the product of a reliable operating model. Technology alone cannot produce the outcomes regulators expect.
Pre-Production Gates
Three gates must exist between development and production. None can be waived without explicit risk acceptance from a named accountable executive.
- Design review: Agent graph, model choices, retrieval design, tool inventory, and risk classification approved by an architecture or AI council.
- Evaluation review: Golden dataset signed off, eval results passing thresholds, abstention behaviour tested, adversarial cases included.
- Production readiness: Observability dashboards live, rollback path tested, incident response runbook published, monitoring thresholds and on-call rotation in place.
KPI Catalogue
| Category | Metric | Cadence |
|---|---|---|
| Latency | P50, P95, P99 end-to-end; per-step breakdown | Real-time dashboard; weekly review |
| Latency | Time to first token (streaming) | Real-time dashboard |
| Quality | End-to-end accuracy on golden set | Per release; monthly trend |
| Quality | Refusal recall on unanswerable set | Per release; monthly trend |
| Quality | Class-level hallucination counts in production sample | Weekly |
| Adoption | Active users; task completion rate | Weekly |
| Adoption | Abandonment rate; escalation-to-human rate | Weekly |
| Cost | Tokens per request; cost per task; cache hit rate | Weekly |
Incident Response
Every AI incident — a publicly visible hallucination, a guardrail failure, a regulatory inquiry — follows a defined runbook: detection, triage, containment, root cause, and remediation. Every incident updates the eval set. Every incident is reviewed in the next governance forum. Nothing is treated as a one-off.
A 90-Day Implementation Roadmap
This roadmap front-loads the investments that pay back most heavily. Resist the temptation to defer eval and observability work. That deferral is the most common cause of failure.
Days 1–30: Establish the Baseline
- Decompose the latency stack for a representative request. Require a flame graph or span breakdown from engineering.
- Build or commission a golden dataset of 100 questions per primary use case, including unanswerable items and adversarial cases.
- Define and publish latency budget and quality thresholds per use case. Get sign-off from the business sponsor.
- Draft the defect taxonomy and the incident response runbook. Walk through both with engineering and business.
- Stand up baseline observability: tracing, per-step timing, prompt and response logging, basic dashboards.
Days 31–60: Mitigate the Dominant Failures
- Run the eval set against the current system and publish results broken down by use case and defect class.
- Implement the two highest-leverage latency mitigations — typically hop reduction and parallel tool calls.
- Implement the two highest-leverage hallucination mitigations — typically retrieval quality improvements and structured outputs.
- Wire eval runs into the CI pipeline so every PR touching agent behaviour is measured.
- Begin weekly review of production samples; categorise every observed failure and feed back into the eval set.
Days 61–90: Institutionalise
- Establish the pre-production gate process and run the first new feature through it end-to-end.
- Map controls to the relevant regulatory frameworks; produce the artefact package for model risk or AI governance review.
- Brief senior management with the three-slide format: outcome, risk, operating model. Include trended metrics.
- Define the operating cadence: daily standups including eval and latency review, weekly business review, monthly executive review, quarterly governance review.
If you do nothing else in 90 days: Build the eval set, wire it into CI, and decompose the latency stack. Every other investment is more valuable once these three exist. Without them, you are operating blind.
Returning to the Path of Business Value
Most agentic enterprise projects do not fail loudly. They drift. The pilot demoed well, the budget was approved, the team grew — and somewhere between month four and month nine the velocity slowed, the accuracy metrics stopped improving, and the sponsor's enthusiasm cooled into polite scheduling.
This drift follows a recognisable pattern:
| Drift Signal | What You Observe | What It Actually Means |
|---|---|---|
| Metric flatlining | Accuracy stalls, latency stalls, eval scores plateau | The team is tuning at the edges; foundational issues remain |
| Escalation collapse | Vague business complaints replace structured defect reports | The feedback loop is broken; operating without ground truth |
| Sponsor disengagement | Executive sends a deputy, asks fewer questions | Business confidence eroding faster than velocity is recovering |
The Three Upfront Disciplines
Planning first. Run the planning conversation with the business sponsor before anything else. The one-sentence test: "In ninety days, [named business metric] will move from X to Y because [named user role] doing [named task] will use this system." If you cannot complete this sentence honestly, you have a roadmap, not a plan. Roadmaps describe activity. Plans commit to outcomes.
Ingestion second. Once the use case is sharp, the corpus required to serve it is knowable, and curation can begin. A system that retrieves badly will hallucinate eloquently — and no prompt engineering will raise the ceiling that retrieval has set.
Inference third. With planning sharp and ingestion strong, inference-time changes — routing, context assembly, validation, abstention — produce compounding improvements that are now measurable against a stable baseline.
A team that reverses this order — tuning inference against a noisy retrieval base, against an unclear use case — will produce improvements that do not survive the next sprint.
The definition that should govern every agentic project: True business value is the difference between a named business metric before deployment and after deployment, sustained over a meaningful operating window. Everything else — accuracy percentages, latency reductions, eval scores, demo applause — is supporting evidence.
That’s the full picture.
More from The Studio
All Papers →
BLACKBOX: The Flight Recorder for AI Agents
When an AI agent makes a wrong decision, enterprises need to answer three questions: what exactly happened, in what order, and can the record be trusted? BLACKBOX provides the infrastructure layer that makes all three answerable. Every event — reasoning step, tool call, output, fault — is sealed into a SHA-256 hash chain. Any alteration to any stored event breaks the chain. Any run can be replayed verbatim. This paper documents the architecture, the three instrumentation paths, the phases completed, and the enterprise case for treating AI agent observability as an insurance requirement, not a nice-to-have.

The Token Economy: A First-Principles Playbook for Governing Claude in Production
At 11:47 PM on a Thursday, a Series C fintech spent its entire monthly inference budget in four hours. The root cause wasn't a malformed JSON — it was the absence of a governance discipline that should have been established before a single line of code was written. This paper specifies that discipline: four levers, one planning artifact, one role, one cadence — in the vocabulary CFOs, CTOs, and Staff+ Engineers already use.
Want to go deeper?
Discuss this paper with my digital twin.
Ask questions, challenge the framework, explore implications.
Open the Digital Twin